Open Access to Research Data
The University Library offers guidance on various aspects of research data handling and data management planning.
Main content
Research data is a core part of the value creation at universities. Promoting open access to research data is a strategy to make full use of their potential and thereby maximise the impact of research activities in a digital society.
The University Libary provides guidance on various aspects of research data handling and data management planning, please do not hesitate to contact us.
WHY should you make your research data open?
Open Access to research data increases the impact and transparency of research activities. It ensures that the full potential of a research project is utilized and can lay basis for further research, with appropriate crediting of the data creators. Therefore, practices to support good data handling and open access to research data have been made a requirement by funding bodies, such as the Norwegian Research Council and the European Commission. In alignment with the National strategy on access and sharing of research data, open access to research data is part of The University of Bergen Policy for Open Science.
Furthermore, many publishers require authors to make the datasets underlying the findings described in their publications available and thereby ensure reproducible research.
"The goal of the University of Bergen is that data resulting from research activity should be made readily available for reuse in accordance with FAIR-principles."
From University of Bergen Policy for Open Science
"More open access to, and wider reuse of, research data promotes scientific advancement in that it equips individual researchers with a larger pool of data, facilitates replication and quality assurance of previous research findings, and prevents re-funding of the same type of data collection multiple times."
From National strategy on access and sharing of research data
Benefits of data sharing & repository use
Open access to research data increases the impact
Open access to research data comes with advantages for both researchers and policy makers:
- Articles that link to research data are cited more often
- Interlinking data and publications increases the visibility of researchers
- Data publications can make data available and citable that is not linked with a publication
- Data or analysis tools can inspire new research and create opportunities for collaborations
- Transparency supports research integrity and reproducibility
- Available results allow involvement of citizens and society
- Fewer resources spent on result duplication, thus greater efficiancy for funding bodies
- Building on results can lead to acceleration of the research process, faster innovation
Further reading:
Piwowar et al., 2013: Data reuse and the open data citation advantage
Colavizza et al., 2020: The citation advantage of linking publications to research data
McKiernan et al., 2016: How open science helps researchers succeed
Allen et al., 2019: Open science challenges, benefits and tips in early career and beyond
Burgelman et al., 2019: Open Science, Open Data, and Open Scholarship: European Policies to Make Science Fit for the Twenty-First Century
Open access to research data is a requirement
Both research institutions and funders have expetations on how research data should be handled and planned: Overview about data management and data management plans
WHAT is research data - should everything be open?
In the National strategy on access and sharing of research data, publicly funded research data is defined as "all data collected or generated for use for or as a result of publicly funded research activities and data underpinning publications that are the result of publicly funded research activities". This includes both entirely new data and data generated through analysis of existing data (secondary data). In order to take full advantage of their potential, research data should be managed and curated.
To accelerate the research process and to make research results reproducible, also research protocols and analysis software/program code created in the research process should be made accessible.
The main principle of open access ot research data is that data should be as open as possible but as closed as necessary. For example, personal or sensitive personal data as well as data that would conflict with intellectual property rights and commercialization can not be made fully openly accessible. However, it might be possible make some sensitive personal data available in anonymized form or to specific users by defined access criteria and ensuring technical access control.
HOW can you make your research data open?
Data management plans (DMP) are an instrument to support good data handling practice throughout the whole research data life cycle, from project planning over the active phase of research to project conclusion. Archiving data, accompanied by their metadata and a suitable data license, is a strategy to increase the impact of research results and promote reproducible research. The FAIR-principles describe a set of guidelines that ensure that research data can be reused. Importantly, FAIR data does not equal unrestricted access to data ("As open as possible, as closed as necessary"). In a project with personal or sensitive personal data, measures to secure the data will be an important part of the data management plan. The University of Bergen as well as funding bodies require that research projects have a DMP. You can find more practical information on our page on DMPs. In addition, the University library regularly provides courses on data management planning.
"All research projects lead by researchers at UiB will have a data management plan."
From University of Bergen Policy for Open Science
The research data life cycle
Research data life cycle describes the process from project and data management planning over creating novel data or creating new knowledge based on existing data to publication and long-term preservation of high-quality research data which again can lay basis for new research projects.
Knowledge clip: The research data lifecycle
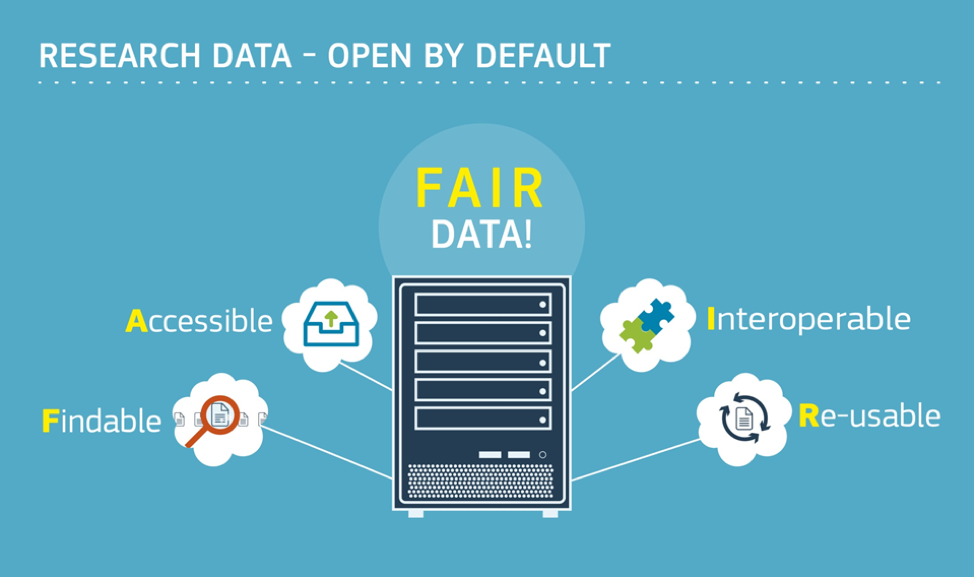
FAIR data: Findable, Accessible, Interoperable, Reusable
The FAIR-principles were published in 2016 (Wilkinson et al.) as a detailed set of guidelines to ensure that archived research data is of sufficient quality.
"UiB will promote open access to research data and the FAIR principles in national and international networks and collaborations."
From University of Bergen Policy for Open Science
The FAIR-principles in brief:
- Findable: Finding datasets is the first step of (re)using datasets. This requires metadata ("data about data"), readable for humans and machines, and persistent identifiers.
- Accessible: Criteria to ensure access to a found dataset. Metadata must be retrievable by a standardized protocol, that allows for authorization procedures were necessary. Importantly, metadata must remain accessible even if the data itself are no longer available.
- Interoperable: Prerequisites to integrate datasets with other data and applications. Metadata should use ontologies/controlled vocabularies and include qualified references to other (meta)data.
- Reusable: FAIR should allow for reuse of data. Metadata must be rich, must contain provenance, and follow community standards. A data usage license ensures legal interoperability.
Obtaining all necessary metadata records in the active phase of research, eases the archiving of FAIR data at project conclusion. It is therefore advised to make yourself familiar with the metadata standards and data archives in your research community already during data management planning.
Data management in the active phase of research
Good data management in the active phase of a research project facilitates your future research, eases collaborations, enables advanced analysis methods, and is a prerequesite for archiving high-quality data. Some aspects to consider:
Data storage and backup
- The IT-department provides information about local data storage at UiB. For additional storage quotas, active storage or cold storage on Billy, see the price list from the IT-department. If you need personal guidance, please contact UiBhjelp.
- Consider if information requires protection. The UiB Storage Guide provides guidance what information should be classified as restricted/ in confidence/ strictly in confidence. The University of Oslo storage guide gives further examples and you can find more information about information sensitivity levels from UNIT.
- Sensitive data from UiB can be stored in SAFE. Please see also the information about personal data and personal sensitive data.
- Active storage of large amounts of data (TB range) is provided by Sigma2, applications run twice per year. The NIRD service platform allows on-site analysis.
- Information about high-performance computing (HPC) at UiB is provided by the Scientific computing group. The Norwegian Research Infrastructure Services ("Metacenter") regularly organizes training events.
- Exchanging files in collaboration projects: FileSender is a national service for transfer of larger files.
File handling
- Use descriptive and informative file names. Organize/index your data in a way that allows you and others to easily search for certain files, also after an extended period of time. Consider machine-readability and automatic sorting.
- Take care of all documentation and metadata that is needed to understand and reproduce the data.
Data documentation and metadata resources: CESSDA Data Management expert guide, RDMkit, The Turing Way - Choose non-proprietary file formats that will ensure long-term access.
- Consider the annotation in your data files and their machine-readability. For example, save tidy data with each variable as a column, each observation as a row, and each observational unit as a table.
- If you write software code, consider version control with Git. The University of Bergen has its own Gitlab instance.
Metadata standards
- Make yourself familiar with the metadata standards in your research community/ in the archive you want to publish your data in already early in the process and make sure to obtain the necessary records. Please see data archiving for more information.
Reproducible research
- Data provenance or data lineage describes the historical record of data from their origin over transformations (such as analysis workflows, integration with other datasets) to their publication. Each data point in an article figure should be tracable to its original aquisition.
- Electronic lab notebooks (ELN) can aid data provenance records in some disciplines.
- Analysis workflows should be reproducible, e.g. by using software code for data analysis and controlled computational environments.
Projects with personal data & personal sensitive data
If projects contain personal data or personal sensitive data, specific measures need to taken to secure the data. Describing these measures are an important part of the data management plan.
Personal sensitive data (Norwegian: særlige kategorier av personopplysninger) describes a category of personal data that contains information about racial or ethnic origin, political beliefs, religion, philosophical beliefs, trade union memberships, genetic and biometric information, health information, or sexual information.
The University of Bergen Info pages on research ethics (the Norwegian page is more comprehensive) collects guidelines and legal information that have to be considered when working with personal (sensitive) research data.
Please see also the UiB Research Ethics pages, the IT department's pages on IT for research and the Personal Data and Privacy's gateway pages on research ethics (in Norwegian).
Importantly, all student and research projects at UiB that contain personal (sensitive) data must be registered and followed up in RETTE. RETTE collects self-completed project information from researchers and students, research projects evaluated by Sikt personverntjenester , and health research projects that have research ethics approval from REK.
If employees become aware of a personal data security breach (Norwegian: brudd på personopplysningssikkerheten), this has to be reported to the respective personnel for further processing upon knowledge. At UiB, this can be done using an online form (see also UiB rules).
Storage of personal (sensitive) data in the active phase of research
The IT department at UiB has a service for secure storage and access to sensitive data, SAFE.
Other secure storage options in Norway are TSD and HUNT Cloud.
Archiving personal (sensitive) data
Long-term preservation of personal (sensitive) data can be appropriate in certain cases. Some sensitive data may be archived in repositories with technical access control to allow data access only for specific users by defined access criteria. In other cases, anonymisation of sensitive data could allow their deposition in an open repository. Importantly, if research data is collected with informed consent, data archiving plans need to be included already in the consent forms.
Resources
The University of Bergen Info page on research ethics (the Norwegian page is more comprehensive) collects guidelines and legal information.
Research routines for projects with personal data: Forskningsrutiner (in Norwegian)
UiB regelsamlingen: Rettslig grunnlag for behandling av personoppsyninger for vitenskapelig forskningsformål (in Norwegian)
The CESSDA Data Management Expert Guide contains a section on legal and ethical considerations in creating shareable personal data.
The UK Data Service has sections on anonymisation of both qualitative and quantitative data.
The ELIXIR RDMkit has sections on sensitive data and planning, collection, processing, analysing, preservation, and reuse of human research data.
PhD on Track about personal data and sensitive data.
Sikt FAQ about data protection and the notification form.
DANS Guidebook: Making Qualitative Data Reusable
Subject-specific support
Although the basic principles apply to all sorts of research data, many aspects of research data management are discipline-specific. Some infrastructures provide specific support services for research data and data management-related questions:
- ELIXIR for life sciences. See also the ELIXIR RDMkit.
- CLARINO Bergen Center for language research
- Bjerknes Climate Data Centre for climate research
- Sikt for social science research. Sikt is the national service provider for the Consortium of European Social Science Data Archives (CESSDA). See also the CESSDA data management expert guide.
- NMDC for marine research
NB! If you feel your infrastructure is missing, please contact us.
WHERE can you make your research data open?
Publishing research data and their accompanying metadata in a research repository ensures their long-term preservation, findability, and accessibility. Research data should be made accessible latest at publication of the scientific article
Choose a data archive
Community repositories, that are optimized for the needs in a given field of research, are often the first choice to archive your data and make your research data visible and findable. re3data.org is the largest and most comprehensive registry of data repositories available on the web. The registry is curated and all listed data repositories meet defined quality criteria. fairsharing.org is an another, curated registry of research data repositories. Furthermore, the Norwegian Research Council has published a road map of research infrastructures (in Norwegian) that links to many relevant repositories.
Institutional repositories are a good alternative to subject-specific repositories. Researchers at UiB can archive data in DataverseNO and get support in the deposition process.
If neither a community repository nor an institutional repository appears suitable, general-purpose repositories can be used. For example, Zenodo is a general-purpose open-access repository developed under the European OpenAIRE program and operated by CERN.
Although it is requested that data is made accessible as early as possible, embargos on the data release can be appropriate sometimes. Embargo periods and reviewer access are supported by most repositories.
Archiving personal (sensitive) data
Long-term preservation of personal sensitive data can be appropriate in certain cases. Some personal sensitive data may be archived in repositories with technical access control to allow data access only for specific users by defined access criteria. In other cases anonymization of sensitive data could allow their deposition in an open repository. Importantly, if research data is collected with informed consent, data archiving plans need to be included already in the consent forms. You can find more information about human data in the research data life cycle and archiving options in the RDMkit: human data.
Persistent file formats: Ensure long-term access
Research data should be archived in open, non-proprietary formats to ensure long term access to the files. For example, TXT rather than Microsoft Word, CSV rather than Microsoft Excel, TIFF or PNG rather than Adobe Photoshop files. For more examples, see the DataverseNO deposit guide.
Metadata: Describe your data
Metadata is structured information that describes, explains, locates, and makes it easier to retrieve and use an information resource.
In order to help make your data reusable and accessible to you and others in the future, you need to create and archive accurate metadata along with your data. If you archive your data in a community repository or institutional repository, most often the repository will define the metadata standard. The Digital Curation Centre allows to browse examples of metadata standards by discipline. Furthermore, fairsharing.org holds a curated registry of metadata standards.
Data licenses: Allow reuse of your data
Reuse of data with appropriate crediting of the data creators requires a license. For research data, mostly Creative Commons licenses are used. Licenses on research data should set as few restrictions as possible on the access, reuse and redistribution of the data. Be aware, that attribution requirements might result in attribution stacking.
For open software licenses, choosealicense.com and the Open Source Initiative provide useful resources.
Citable Code
To ensure long-term preservation and allow citation, it is recommended to publish program code that was generated during a research project. Many researchers use Git, a system for distributed version control, to manage their program code. The online development platforms Github and Gitlab (beta) have implemented comfortable release functions to publish code on the general-purpose repository Zenodo, supporting versioning.
Good code documentation is crucial to make program code reusable. CodeRefinery provides more information and a checklist.
Contact & Guidance
Contact us at research-data@uib.no
UiB's institutional research data archive
Data Management Plans
Practical information: Data Management Plan
Open Science webinars spring 2026
Welcome to the UiB Library Open Science webinars includig regular courses on Research Data Management.
Presentation slides from past courses are available on Zenodo.
Norwegian Open Science event calender with interesting events at other institutions.
Courses on request
We can adapt courses specifically for your institute or research group - contact research-data@uib.no
National resources:
openscience.no
PhD on Track on Research data.
Network
Do you work with data management support in Bergen? Join the Research data network in Bergen.